5 products. ~3 months. Solo.
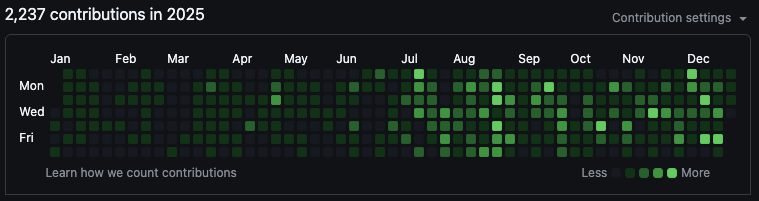
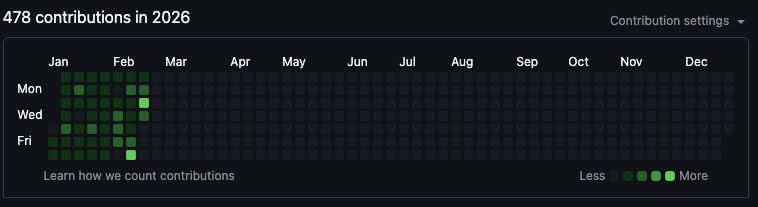
commits (Peekaboo alone)
specialist AI agents
person
These principles work across all of these tools. The handbook pattern, the guardrails, the review process — they're universal.
But my preference is Claude Code and the Claude CLI.
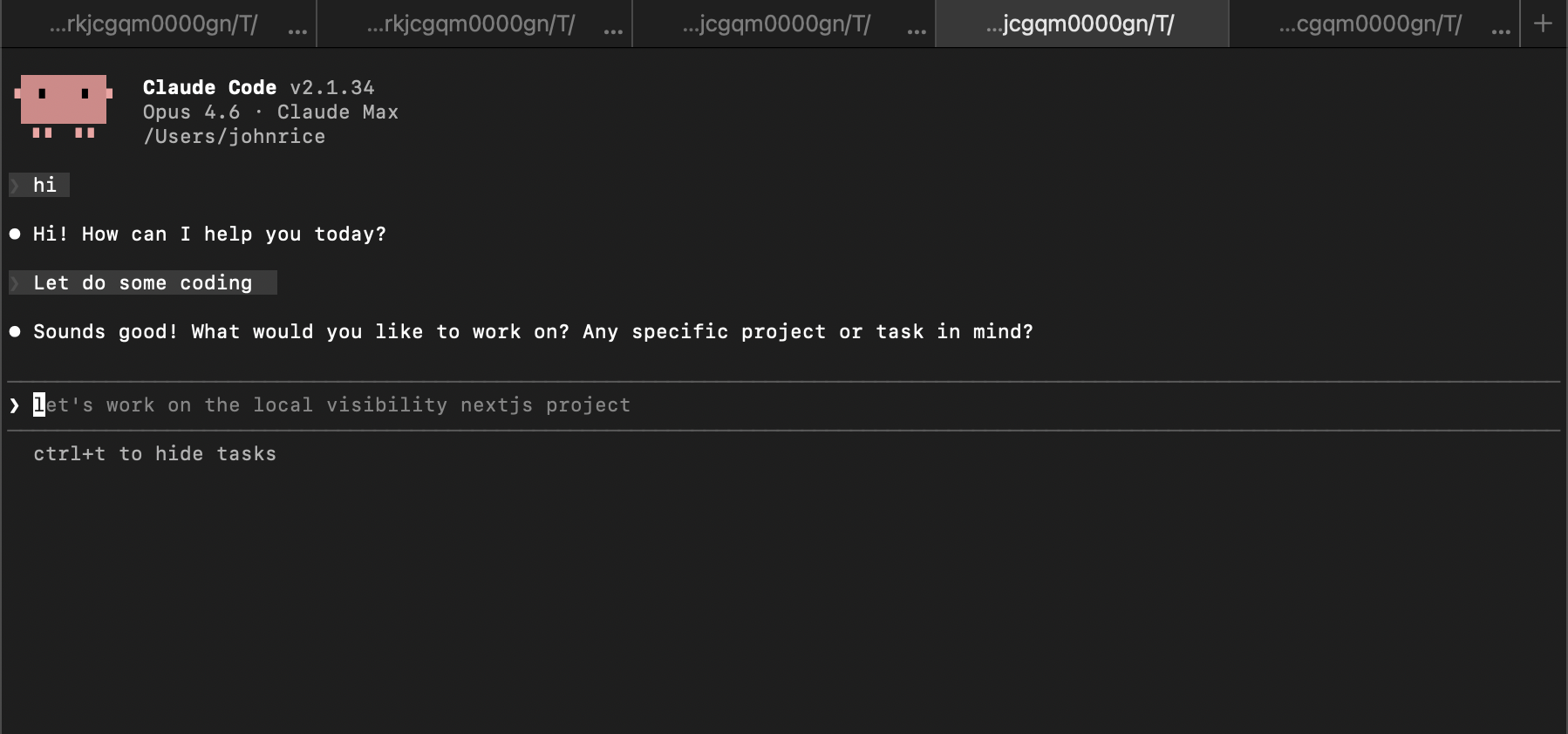
Claude Code — Opus 4.6 in the terminal
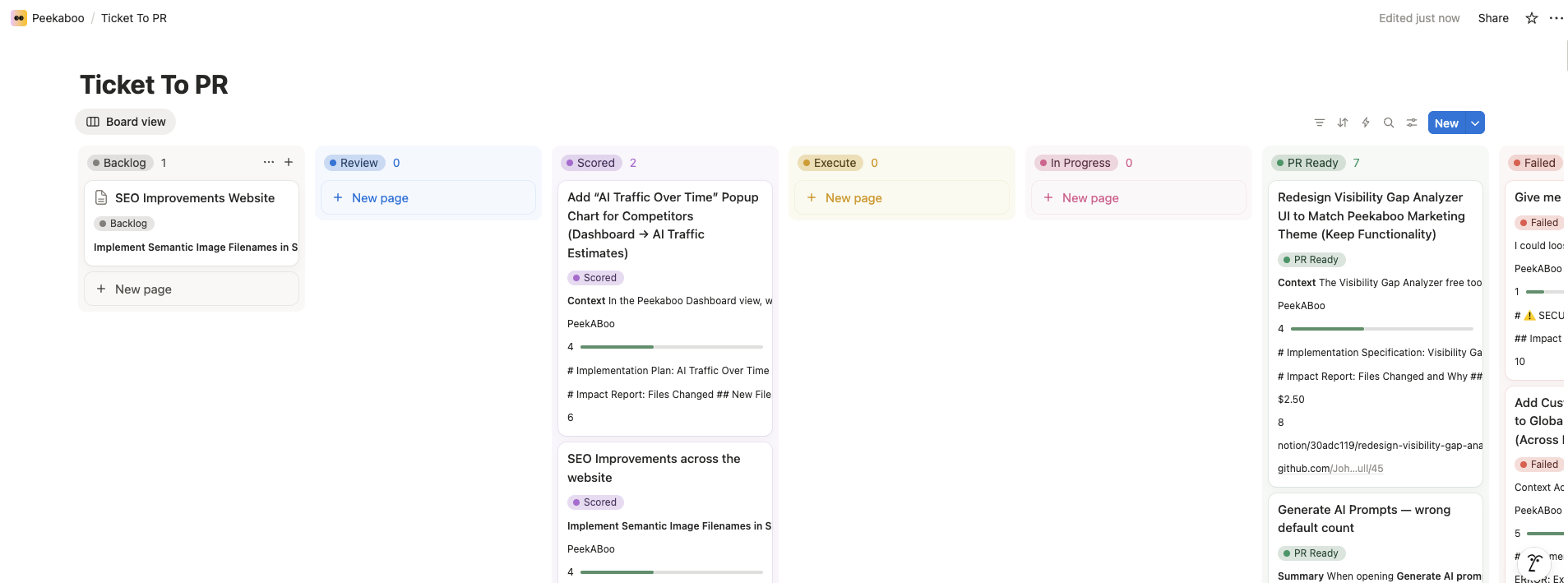
Plain English tickets in Notion. AI handles everything in between.
Brand visibility analytics across 5 AI platforms. 1,162 commits, 13 agents.
Notion-to-PR automation. AI scores feasibility, builds features, creates PRs. On npm.
Reddit lead intelligence. AI-scored leads, sentiment analysis, estimated deal value.
AI-powered personalized children's stories. Custom illustrations and interactive reading.
Local business discovery platform. Location-based recommendations and search.
Reddit content strategy & scheduling. AI-powered subreddit analysis and auto-posting.
All built with the same approach: CLAUDE.md + specialist agents + human review.
10M+
sources analyzed
3M+
AI responses
5
AI models
24/7
automated
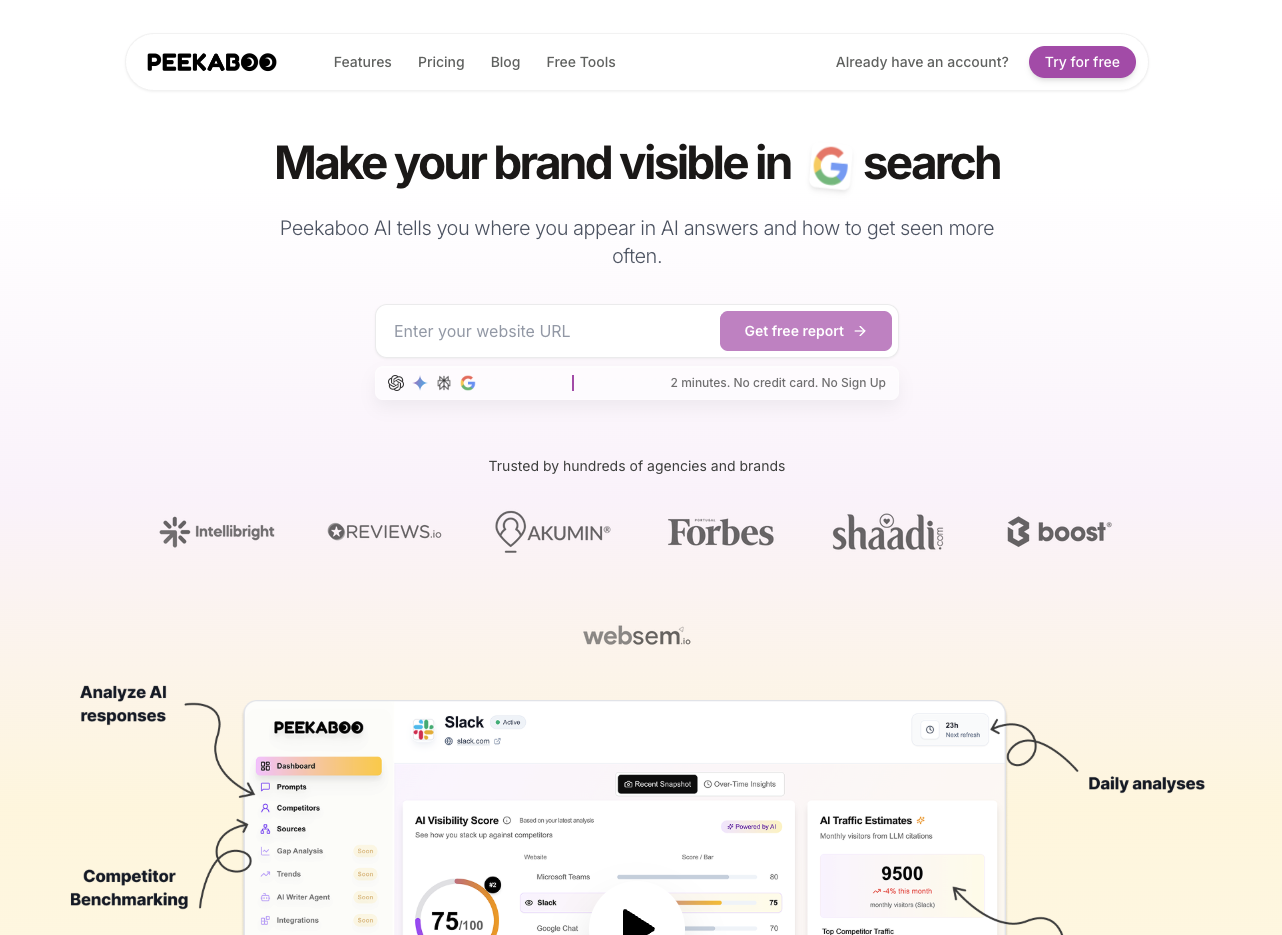
What Peekaboo tracks
How brands appear in ChatGPT, Gemini, Perplexity, Google AI Mode, and Google AI Overview. Competitive intelligence, visibility scoring, traffic estimates.
Traditional equivalent
3–5 developers, 4–6 months, $200K+ in salary. Built by one person + AI agents at a fraction of the cost.

📖 AI Agent Playbook
Free templates, guides & examples

![]() Peekaboo
Peekaboo
aipeekaboo.com

![]() TicketToPR
TicketToPR
tickettopr.com
Thank you! Questions?